Настройка параметров ядра#
Предупреждение
Данный раздел находится в разработке и предназначен для опытных пользователей Linux, которые хотят выполнить более тонкую настройку системы. Тем не менее, в нем автор немного упростил внутреннюю картину работы ядра, чтобы не делать текст чрезмерно объемным и сложным для понимания простому пользователю. Так, например, здесь вы увидите несколько упрощенную модель устройства виртуальной памяти ядра Linux, поэтому если вы эксперт в вопросе, то не судите строго.
Введение#
Как и любая другая программа, ядро имеет свои собственные настройки и параметры, которые контролируют поведение определенных его частей. И хотя настройки ядра Linux являются менее очевидными для понимания и часто "скрыты" с глаз обычных пользователей, в данном разделе мы рассмотрим различные настройки ядра с целью улучшения производительности и отзывчивости системы для домашнего ПК или ноутбука, подобрав наиболее оптимальные значения в зависимости от вашей конфигурации.
Как мы поймем далее, несмотря на то, что ядро Linux принято считать монолитным, все настройки ядра относятся к определенным его подсистемам, поэтому раздел будет разбит на систематические блоки, каждый из которых будет выполнять настройку конкретной подсистемы, будь то подсистема ввод/вывода или сети.
Стоит также отметить, что так как ядро является общей составляющей
всех дистрибутивов Linux, то почти вся информация которая будет
представлена в этом разделе применима не только к Arch Linux, но и к
другим дистрибутивам. Учтите, что некоторые параметры зависят от вашей
версии ядра, которая, по понятным причинам, от одного дистрибутива к
другому может отличаться, поэтому обращайте внимание на примечания, где
указано с какой версии появился тот или иной параметр. Узнать
версию используемого вами ядра можно через команду uname -r.
Зачем?#
Часто люди задаются вопросом, зачем пытаться лезть под капот, когда "очевидно", что все уже настроено и отполировано за тебя. Отчасти это правда, и ядро Linux с каждой версией улучшается и "вылизывается" тысячами разработчиками по всему миру, и, наверное, параметры о которых пойдет речь далее уже имеют наиболее оптимальные значения. Но к сожалению, это не совсем так. Или скорее совсем не так. Во-первых, разработчики ядра часто не могут иметь представления о том, на каком конкретном железе будет работать ядро и для каких целей оно будет использоваться, в следствии чего главным приоритетом при разработке является совместимость и адаптивность ядра к как можно большему числу возможных задач и конфигураций. Такой компромиссный подход к разработке не всегда дает наилучшие результаты в чем-то конкретном, но зато позволяет ядру Linux одинаково подходить как для работы на серверах, роутерах, телефонах, микроконтроллерах, так и простых ПК. Грубо говоря, ядро Linux представляет собой швейцарский нож от мира IT, которым хоть и можно порезать хлеб, но удобнее это сделать обычным ножом. Наша задача в данном разделе это как раз заточить ядро под конкретную задачу, в нашем случае это интерактивное использование на домашнем компьютере.
Если вы переживаете за стабильность вашей системы, то предварительно сделайте резервную копию, хотя на самом деле все параметры, о которых пойдет речь далее, могут быть отключены в любой момент простым удалением файла настройки, поэтому даже при возникновении проблем со стабильностью или регрессиями у вас не должно возникнуть проблем с откатом к стоковым значениям.
Виды настроек#
В ядре Linux все параметры можно поделить на типы в зависимости от
способа установки их значения [1]. Часть из них может быть
установлена только на этапе загрузки ядра, то есть в качестве опций
командой строки [2]. Это то, что мы обычно пониманием под просто
"параметрами ядра". Они указываются в настройках вашего загрузчика,
будь то GRUB, refind или systemd-boot. К этой же категории можно
отнести параметры модулей ядра, значения к которым передаются во время
их загрузки. При этом значения параметров могут быть переданы как
часть общих параметров загрузки ядра в конфиге вашего загрузчика при
их указании в следующем формате: module.parameter=value (например
nvidia-drm.modeset=1). То есть сначала указывается имя модуля
(драйвера), затем имя параметра и через знак равно передается
значение. Другой способ передачи параметров для модулей - это
использование конфигурационных файлов modprobe. В этом случае не
имеет значения какой у вас загрузчик, достаточно создать файл в
директории /etc/modprobe.d с любым названием, и прописать
параметры в следующем формате:
options module parameter1=value1 parameter2=value2
Именно вторым способом передачи параметров по возможности мы будем пользоваться далее в разделе, когда речь будет заходить о настройке различных модулей.
sysctl#
Другой тип, это параметры, значение которых можно изменить прямо во
время работы системы, что называется "на лету". Такие настройки
представлены в виде файлов на псевдофайловой системе procfs в
директории /proc/sys [3]. procfs называется псевдофайловой
потому, что физически она не расположена на диске, а все файлы и
директории создаются самим ядром при запуске системы в оперативной
памяти. По этой причине у них отсутствует размер, и все они имеют
чисто служебный характер. В директории /proc/sys/ каждая настройка
это отдельный файл, куда мы должны просто передать (записать) значение
в виде числа (часто 1 и 0 означают включить/выключить, но некоторые
параметры также могут принимать значение, которое имеет строго определенный
смысл, и только из определенного диапазона). Все настройки объедены в
директории, которые характеризуют их отношение к чему-то общему.
Например, все файлы в подкаталоге vm - это настройки для механизма
виртуальной памяти ядра [4] , включая настройки для подкачки,
кэширования, и т. д. В kernel - общие настройки ядра [5], а в
net [6] - настройки сетевой подсистемы, протоколов TCP и IP.
Именно эти три категории мы и будем рассматривать далее.
Конечно, процесс поиска всех файлов-настроек и записи значений
средствами командой строки каждый раз весьма утомителен. Поэтому
разработчики создали специальную утилиту под названием sysctl,
которая значительно упрощает данный процесс. Теперь нам не нужно
лазить каждый раз в /proc/sys/, чтобы изменить значение
параметров. Вместо этого достаточно прописать в терминале:
sysctl -w kernel.sysrq=1
Это то же самое, что и данная команда, которая прописывает значение
напрямую в файл из директории /proc/sys/:
echo "1" > /proc/sys/kernel/sysrq
Обратите внимание, что для изменения настроек всегда нужны права root,
поэтому перед каждой такой командой мы должны добавить sudo:
sudo sysctl -w kernel.sysrq=1
Другим преимуществом sysctl является то, что мы можем делать такие
изменения постоянными, просто прописав соответствующую строку в файл,
который находится в директории /etc/sysctl.d/, например в
/etc/sysctl.d/99-sysctl.conf:
kernel.sysrq = 1
Собственно именно добавлением таких строк мы и будем применять соответствующие настройки.
Предупреждение
Настройки прописываемые в файле /etc/sysctl.conf не
применяются начиная с версии 21x в systemd, поэтому
прописывайте их только в файлах, которые расположены в подкаталоге
/etc/sysctl.d. Имя файла не имеет значения.
tmpfiles.d#
К сожалению, далеко не все настройки ядра можно изменить при помощи
sysctl или псевдофайловой ФС /proc/sys. Часть из них является
отладочными, поэтому они расположены в виде файлов на другой
псевдофайловой системе - sysfs, которая в основном отвечает за
представление информации об устройствах, которыми управляет ядро. В
директории в /sys/kernel представлены ряд других полезных
параметров, которые мы рассмотрим в рамках общей темы. Чтобы выполнить
установку значения в файлах, которые находятся в /sys/kernel/, мы
будем использовать такой инструмент как systemd-tmpfiles.d [7]. Он
есть только в дистрибутивах, использующих systemd в качестве системы
инициализации, то есть в большей части дистрибутивов Linux включая
Arch. Суть этой службы состоит в управлении, создании и удалении
временных файлов или редактировании уже существующих. В нашем случае
мы будем его использовать для записи значений в файлы настроек
расположенных в /sys/kernel/. Для этого, по аналогии с sysctl,
нужно создать файл в директории /etc/tmpfiles.d, например
/etc/tmpfiles.d/99-settings.conf. Формат записи каждой строки в
файле будет следующим:
w! /sys/kernel/mm/lru_gen/min_ttl_ms - - - - 2000
Первый символ - это тип действия, который systemd-tmpfiles будет
выполнять с указанным по пути файлом. В нашем случае мы будем
использовать только запись w некоторого значения в уже существующие
файлы, а не создавать новые. Восклицательный знак ! указывает, что
значение будет прописываться только один раз при загрузке системы.
После пути до файла идут четыре прочерка, в них должны быть указаны
права доступа, которые мы хотим изменить, но так как мы имеем
дело со служебными файлами, то пишем везде прочерки, чтобы ничего не
менять. В конце указываем значение, которое будет прописано в файл, то
есть значение параметра.
Другими словами, везде, куда не дотянется sysctl, мы будем
использовать tmpfiles.
udev#
По сути первых двух инструментов уже достаточно, чтобы выполнить
полную настройку ядра, но мы используем ещё одну вещь - правила udev.
Udev [8] - менеджер для управления вашими устройствами, который
отслеживает их подключение/выключение, и предоставляет возможность
создавать так называемые "правила", которые вызываются каждый раз,
когда происходит определенное действие с тем или иным устройством.
Внутри этого правила можно указать, при каких событиях и для какого
конкретно устройства (условие для срабатывания) мы будем выполнять
определенную команду или устанавливать некоторое значение. Это очень
полезный инструмент, который позволит нам применять целый ряд настроек
в зависимости от некоторых условий и подстраиваясь под железо, которое
у вас есть в системе. Приведу пример, чтобы стало понятнее. Для разных
типов носителей подходит разный планировщик ввода/вывода. Для обычных
SSD - mq-deadline, для HDD - bfq. Правила udev позволят нам
при подключении определенного типа устройства сразу выбирать нужный
планировщик и дополнительные параметры для него, даже если у вас в
системе есть и SSD, и HDD одновременно. Подробнее планировщики
ввода/вывода будут рассмотрены далее вместе с синтаксисом самих
правил.
Оптимизация ввода/вывода#
Фууух, что же, надеюсь вы не устали от всего этого скучного вступления выше и мы можем наконец-то переходить к сути. Начнем с оптимизации ввода/вывода, то бишь к настройке подкачки (она же своп, от англ. swap), различных кэшей и планировщиков.
Общие сведения#
Прежде чем перейти непосредственно к настройке необходимо понять принцип работы механизма виртуальной памяти и подкачки в Linux. Это важно, так как в этой теме ходит целая куча различных мифов, которые мы сейчас разберем.
Итак, для начала чрезвычайно важно понять, что ядро Linux разбивает всю вашу память на маленькие "гранулы" - страницы памяти, как правило по 4 КБ (для x86 архитектуры), не больше и не меньше. Это может показаться странным, но если не вдаваться в технические подробности, то такой подход позволяет ядру Linux проявлять достаточно большую гибкость, так как данные страницы могут быть одинаково обработаны ядром вне зависимости от того, что в них записано, предотвращая обильную фрагментацию. Тем не менее, все страницы памяти можно разбить на несколько типов. Сейчас мы не будем рассматривать их все, но остановимся на самых главных:
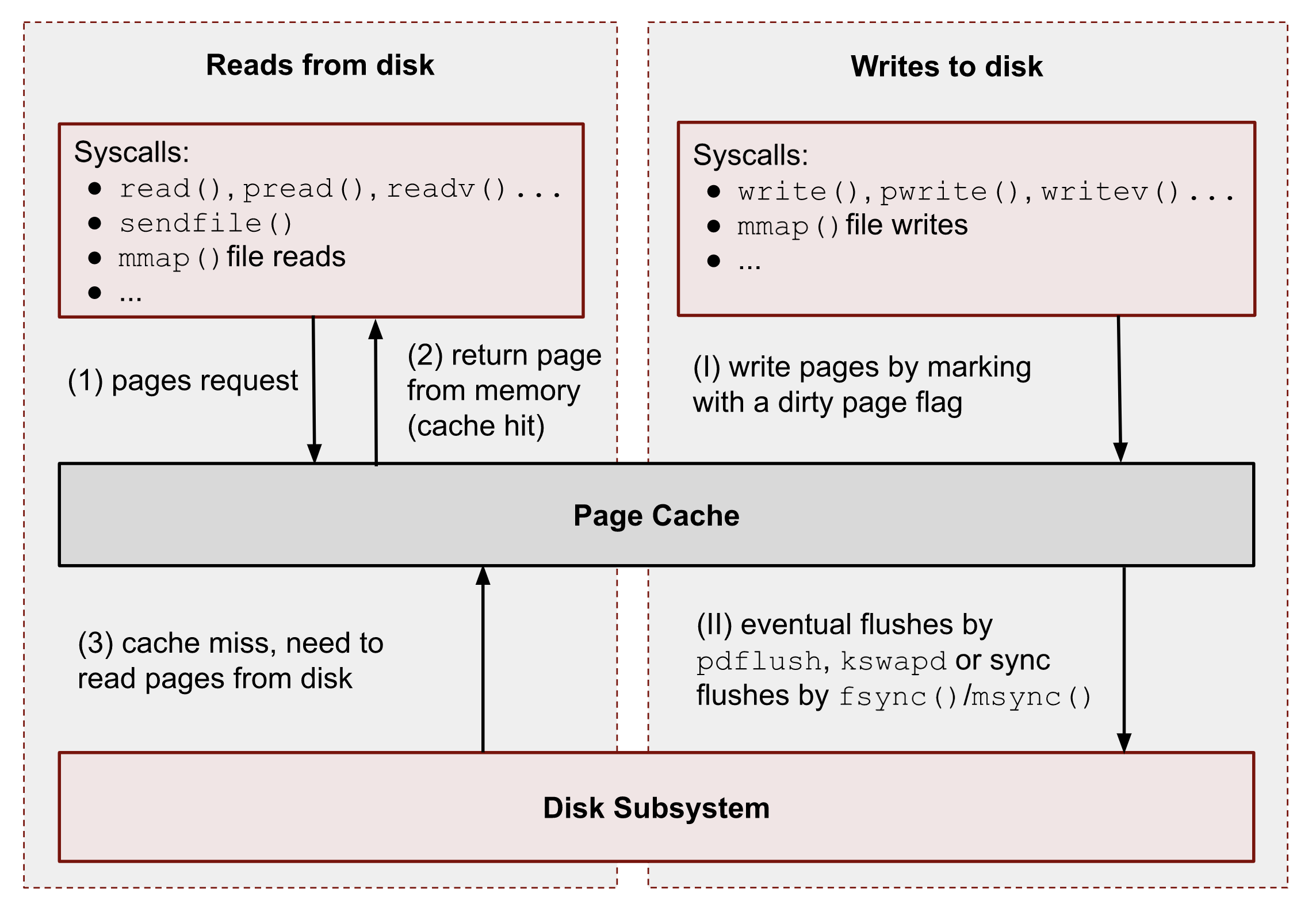
Файловая "подложка" или файловые страницы - это страницы в которых ядро "отображает", то есть представляет данные файла, считываемые с диска в виде страниц в памяти. С этими страницами тесно связано понятие страничного кэша (page cache) [9]. Если некоторый процесс открывает какой-то новый файл и читает из него информацию, то в первый раз ядро считывает эти данные с диска и сохраняет их в страничном кэше, а все последующие операции ввода и вывода к этим же данным будут осуществляться уже при использовании кэша, что значительно ускоряет все базовые операции чтения и записи, предотвращая повторные обращения к диску. При этом память для таких страниц выделяется по требованию, поэтому если процесс открыл файл, но ничего из него не читает, то никакой реальной памяти для таких страниц выделено не будет. Собственно, то, что вы видите в графе "Кэш" в любой программе аналоге системного монитора в Linux - и есть страничный кэш. Обратите внимание, что исполняемые файлы (программы) тоже загружаются в память как файловые страницы.
(Licensed under the CC BY-NC 4.0. © Vladislav Biriukov, All rights reserved)
Очевидно, что далеко не все данные, которыми оперирует программа, могут быть представлены в виде реальных файлов на диске, поэтому были созданы анонимные страницы, которые, как следует из названия, не ассоциированы с файлами [10]. Программы запрашивают их у ядра во время своей работы для динамических данных. Если вы разработчик, то вы наверняка сталкивались с такими понятиями как "Куча" (Heap) и "Стек" (Stack). Так вот, ядро хранит данные из кучи и стека именно в анонимных страницах памяти.
Грязные страницы (dirty pages) - по сути это подвид файловых страниц, ключевое отличие которых состоит в том, что программы в них пишут какие-то изменения, а так как ядро кэширует все данные считываемые из файлов во избежание излишней нагрузки на диск, то изменения, которые программа делает с файлом, на самом деле происходят сначала в кэше, и только потом синхронизируются с реальным файлом на диске. Более подробно об этом виде страниц и процессе их синхронизации с диском мы поговорим в следующем разделе.
Вернемся к подкачке. Один из самых больших мифов, связанных с подкачкой, состоит в том, что пользователи рассматривают её как некую "дополнительную память", которую свободно можно использовать в случае нехватки реальной, то есть физической памяти. Это конечно же не так, хотя бы потому, что процессор имеет доступ к оперированию только данными, которые находятся внутри ОЗУ. В случае нехватки памяти у ядра есть по сути всего один вариант - это освобождать уже имеющуюся память от тех страниц, которые не используются в данный момент, выгружая их в область на диске которую мы и называем подкачкой. Да, память не берется из воздуха, и подкачка - это просто "чердак", куда ядро скидывает все неиспользуемые вещи, чтобы освободить место для новых или более часто используемых страниц. При этом для процессов не меняется ровным счетом ничего, ибо они как и раньше могут обратиться к данным в памяти, которые были расположены на странице, которая была вытеснена ядром в подкачку, но когда процесс это сделает, ядро найдет эту страницу, считает её из подкачки и обратно загрузит в оперативную память. Это ещё одно преимущество механизма виртуальной памяти, повсеместно используемого ядром Linux.
Вопрос лишь в том, какие именно страницы нужно "вытеснить" из памяти. На самом деле, это достаточно сложный вопрос. Прежде всего, конечно же это будут именно анонимные страницы, так как файловые страницы и так по сути ассоциированы с данными на диске, следовательно в случае чего их точно так же можно повторно считать, и выгружать их в подкачку просто не имеет никакого смысла, что и происходит на практике. Но что если анонимных страниц много, а часть из них реально используется программами в данный момент? Какие из них тогда должны первым делом попасть в подкачку? На данный и многие другие вопросы отвечает специальный алгоритм в ядре Linux, называемый LRU (а поныне и MGLRU). Если очень упрощенно, то данный алгоритм ведет учет использования каждой страницы, то есть количество обращений к ней, и на основе данной статистики предполагает, какие из них реже всего используются процессами, и следовательно какие из них можно без проблем выгрузить в подкачку.
Рядовые пользователи часто не до конца понимают, какие именно данные расположены у них в подкачке. Теперь мы можем дать чёткий ответ: в подкачке хранятся только неиспользуемые анонимные страницы памяти.
Настройка подкачки#
Мы разобрались с основополагающими понятиями, и наконец-то можем
переходить к настройке. Для настройки поведения подкачки используется
параметр sysctl vm.swappiness (значение по умолчанию 60) [4]. Вокруг
него так же ходит целый ряд заблуждений, что приводит к неправильным
умозаключениям. Итак, во-первых, vm.swappiness напрямую никак не
влияет на то, когда у вас начнет использоваться подкачка, то есть его
значение - это вовсе не процент занятой памяти, при достижении которого
начинает использоваться подкачка. Ядро всегда начинает использовать
подкачку только в ситуациях нехватки памяти (это, как правило, когда
занято 85-90% ОЗУ).
Во-вторых, параметр vm.swappiness влияет только на предпочтение
ядра к вытеснению определенного типа страниц в случае этой самой
нехватки. Он принимает значения от 0 до 200 (начиная с версии
ядра 5.8 и выше, до этого максимальным значением было 100). Для более
наглядного понимания, параметр vm.swappiness можно представить в
виде весов, где более низкие (ниже 100) значения приводят к склонности
ядра сначала вытеснять все страницы из файлового кэша, а более высокие
(больше 100) - освобождение анонимных страниц из памяти в подкачку [11].
Значение 100 - это своего рода баланс, при котором ядро будет в
одинаковой степени стараться вытеснять как файловые, так и анонимные
страницы.
Другим крайне распространенным заблуждением является то, что более
низкие значения vm.swappiness уменьшают использование подкачки -
следовательно уменьшается нагрузка на диск, и что это якобы
увеличивает отзывчивость системы. На деле это лишь на половину правда,
так как, да, ядро при низких значениях старается откладывать
использование подкачки, хотя это и не значит, что она вообще не будет
использоваться, но важно понять, что это происходит за счёт более
агрессивного вытеснения файловых страниц из страничного кэша - что
точно так же приводит к нагрузке на ввод/вывод. Почему? Потому что
каждый раз, когда ядро вытесняет страницу из страничного кэша, это
приводит к тому, что все ранее хранящиеся в ней данные снова придется
считывать с диска по новой.
Во-вторых, нагрузка на ввод/вывод, которую создаёт подкачка оказывается слишком переоценена. Для современных SSD накопителей переварить такую нагрузку без замедления работы системы не составит труда. Тем не менее, если страница была вытеснена в подкачку, то любая операция обращения к ней будет в разы медленнее, чем если бы она находилась в ОЗУ, даже если ваш носитель это NVMe накопитель, то операция записи страницы в файл/раздел подкачки и последующая операция чтения из него будет в любом случае затратна. Но даже если у вас HDD, то вам на помощь спешит Zswap - ещё один встроенный механизм ядра Linux, позволяющий значительно снизить нагрузку на диск и ускорить процесс вытеснения. Он представляет собой буфер в памяти, в который попадают анонимные страницы, которые на самом деле должны были попасть в подкачку на диске, и сжимаются внутри него, экономя тем самым драгоценную память насколько это возможно. Если пул страниц Zswap заполнится (по умолчанию он равен 20%), то ядро выполнит выгрузку страниц из Zswap в подкачку [12].
На сегодняшний день механизм Zswap используется во многих дистрибутивах Linux по умолчанию, в том числе в Arch, просто вы об этом могли не знать, и потому могли думать, что ядро "насилует" ваш диск при малейшем использовании подкачки. Никакой дополнительной настройки для его работы как правило не требуется.
Учитывая всё вышеперечисленное, автор рекомендует устанавливать
значение vm.swappiness в 100. Это позволит ядру равномерно
вытеснять в подкачку оба типа страниц. В современных реалиях
выкручивание параметра в низкие значения не приводит к желаемому
эффекту. Конечно, всё индивидуально, и имеет смысл поиграться на своем
железе, чтобы понять что лучше подходит лично вам имея прописанный
багаж знаний по теме. Зафиксировать это значение можно через конфиг
sysctl:
/etc/sysctl.d/90-sysctl.conf#vm.swappiness = 100
Предупреждение
Автор настоятельно не рекомендует устанавливать значение параметра в 0 или отключать подкачку вовсе. Подробнее о том, почему это вредно читайте в данной статье - https://habr.com/ru/company/flant/blog/348324/. Если вы хотите минимизировать использование подкачки чтобы минимизировать нагрузку на ввод/вывод, то используйте ZRAM, о котором пойдет речь далее.
ZRAM#
Но что делать, если у вас и правда очень медленный носитель или вы хотите минимизировать нагрузку на ввод/вывод и износ диска? В этом случае лучшим решением является использование ZRAM - вида подкачки, при котором все неиспользуемые анонимные страницы не выгружаются на диск, а сжимаются прямо внутри памяти при помощи алгоритмов сжатия без потерь [13]. Точно так же как вы сжимаете простые файлы через архиватор, то же самое делает ядро со страницами памяти. Понятно, что уже сжатые страницы использовать нельзя, поэтому если они снова понадобятся процессу, то ядру придется их расжать перед использованием. Конечно, стоит учитывать, что сжатие и расжатие страниц происходит ресурсами процессора, и это имеет определенные накладные расходы, но они довольно несущественны для современных многоядерных процессоров, чтобы ими можно было пренебречь. Тем не менее, всегда можно выбрать более "легковесный" алгоритм сжатия.
Примечание
Некоторые пользователи задаются вопросом: В чем разница между zswap и ZRAM? На самом деле хотя они и занимаются по сути одной и той же работой, разница здесь в том, что Zswap является сжатым буфером в памяти, то есть промежуточным звеном между памятью и подкачкой, которое призвано помочь минимизировать нагрузку на ввод/вывод, а не заменить обычную подкачку на диске целиком как это делает ZRAM. Вытеснная страница при включенном Zswap имеет следующий цикл жизни: RAM -> Zswap -> Подкачка. Если процесс обратиться к странице, которая была вытеснена в Zswap, но которая так и не попала в подкачку на диске, то тогда ядро просто распакует её внутри памяти готовой для использования. В случае если она всё таки была вытеснена на диск, ядро считает её с диска и загрузит в память, как это обычно и происходит без zswap.
Об установке ZRAM было уже коротко рассказано в разделе
Настройка служб. Однако не во всех дистрибутивах Linux есть служба
zram-generator, поэтому покажем универсальный способ его
настройки, основанный на обычных правилах udev.
Прежде чем мы перейдем к настройке ZRAM надо уточнить, что
одновременное использование ZRAM и zswap имеет неопределенный эффект.
С одной стороны, это вполне возможно, и в этом случае Zswap становится
промежуточным буфером уже для ZRAM, но это не имеет особого смысла,
так как они оба занимаются одним и тем же - сжатием данных внутри ОЗУ.
ZRAM также ведет свою статистику о том, какие страницы и в каком
количестве были сжаты, и которая может быть искажена, в силу того что
помимо него в системе может работать Zswap, поэтому настоятельно
рекомендуется его отключить перед использованием ZRAM. Для этого
достаточно указать параметр ядра zswap.enabled=0 в конфиге вашего
загрузчика, либо деактивировать прямо во время работы системы:
echo 0 > /sys/module/zswap/parameters/enabled
Если у вас затруднения с настройкой вашего загрузчика (а такое вполне
может быть на атомарных системах), то вы можете настроить его
перманентное отключение через создание файла в директории
/etc/tmpfiles.d со следующим содержимым:
/etc/tmpfiles.d/90-disable-zswap.conf#w! /sys/module/zswap/parameters/enabled - - - - 0
Примечание
Важно отметить, что для использования ZRAM вам вовсе не
обязательно отключать обычную подкачку, если она у вас до этого
была настроена. В этом случае ядро по умолчанию будет использовать
в качестве основной подкачки тот раздел или файл, примонтированный
в служебную точку монтирования [swap], который имеет приоритет
выше, чем другой. Поэтому если вы установите для ZRAM приоритет
100, как мы это сделаем ниже в файле /etc/fstab, то обычная
подкачка на диске станет использоваться ядром только как запасная в
случае если ZRAM переполнится, либо при использовании функции
гибернации, которая может работать только с подкачкой на диске.
Перейдем к настройке ZRAM. Обратите внимание, что среди "мейнстримных"
дистрибутивов Linux (например таких как Fedora) ZRAM начинают
использовать по умолчанию вместо или вместе с обычной подкачкой на
диске. ZRAM так же используется по умолчанию в качестве подкачки после
установки системы через archinstall. Поэтому сначала проверьте, не
задействован ли уже ZRAM в вашей системе. Сделать это можно очень
просто через команду zramctl, либо проверив по наличию файла
/dev/zram0, который представляет собой блочное устройство куда
будут попадать все вытесняемые ядром страницы (этакий виртуальный
раздел подкачки).
Если же нет, то продолжаем. Для начала нам нужно форсировать загрузку
модуля ZRAM, для этого нужно создать файл в директории
/etc/modules-load.d/30-zram.conf и прописать в него всего одну
строчку:
/etc/modules-load.d/30-zram.conf#zram
Теперь используя правила udev, мы будем создавать наше блочное
устройство /dev/zram0 и делать из него раздел подкачки. Для этого
создадим файл в директории /etc/udev/rules.d/30-zram.rules:
/etc/udev/rules.d/30-zram.rules#ACTION=="add", KERNEL=="zram0", ATTR{comp_algorithm}="zstd", \
ATTR{disksize}="8G", \
RUN="/usr/bin/mkswap -U clear /dev/%k", TAG+="systemd"
Теперь подробно о том, что из себя представляет само udev правило. В
начале мы указываем при каком действии мы хотим, чтобы оно
срабатывало. В нашем случае это ACTION=="add", то есть появление
нового блочного устройства под названием KERNEL=="zram0". Это
блочное устройство создается ядром автоматически при загрузке модуля
ZRAM, форсированную загрузку которого мы уже прописали выше. Здесь
можно заметить, что все проверки в правилах udev осуществляются через
==.
А дальше мы говорим, что в этом случае нужно делать. Во-первых, мы
меняем значение атрибута (в udev правилах все они пишутся как
ATTR{name}, где name - имя атрибута) comp_algorithm нашего
блочного устройства, который указывает на используемый алгоритм
сжатия. Для ZRAM в ядре предложены три алгоритма сжатия: lzo,
lz4, zstd. В подавляющем большинстве случаев вы должны
использовать только zstd, так как это наиболее оптимальный
алгоритм по соотношению скорости/эффективности сжатия. LZ4 может быть
быстрее при расжатии, но в остальном он не имеет больших преимуществ.
LZO следует использовать только на очень слабых процессорах, которые
просто не тянут сжатие большого объема страниц через Zstd.
Следующим атрибутом мы меняем disksize - это размер блочного
устройства. Теперь очень важно: размер блочного устройства - это тот
объем несжатых страниц, который может попасть внутрь ZRAM, и он
может быть равен объему ОЗУ или даже быть в два раза больше него. Как
это возможно? Представим, что у вас 4 Гб ОЗУ. Вы устанавливаете объем
ZRAM тоже в 4 Гб. Вы полностью забиваете всю свою память, открывая 300
вкладок в Chromium, и любой системный монитор или аналог htop
покажет вам, что подкачка тоже полностью забита, но проблема в том,
что это тот размер страниц, которые попали в ZRAM до сжатия. То есть на
деле у вас в ОЗУ вытесненные страницы занимают в разы меньший объем
из-за сжатия. Увидеть это можно через команду zramctl, вывод
которой может быть следующим:
NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
/dev/zram0 zstd 15G 1G 232M 243.3M 16 [SWAP]
Здесь колонка DATA показывает какой объем страниц попал в
/dev/zram0. Если вы опять откроете htop или другой аналог
системного монитора, то вы увидите точно такой же объем того сколько у
вас "занято" подкачки, но вот колонка COMPR показывает уже
реальный размер вытесненных внутрь ZRAM страниц после сжатия,
который очевидно будет меньше в 2-3 раза. Именно поэтому я рекомендую
вам установить объем блочного устройства ZRAM, который в два раза
больше, чем объем всей вашей памяти (Значение 8Gb - это лишь
пример, замените его на то, какой объем вашей памяти и умножьте
это на два). Конечно, здесь нужно оговориться, что не все страницы
бывают так уж хорошо сжимаемыми, но в большинстве случаев они будут
помещаться без каких-либо проблем.
Надеюсь это добавило понимание того, почему не всегда нужно верить
цифрам, которые вам говорит, например, команда free. Завершает наше
udev правило действие, которое мы хотим сделать с нашим блочным
устройством - запустить команду mkswap, чтобы сделать из нашего
/dev/zram0 раздел подкачки.
Всё, что нам осталось теперь - это добавить запись в /etc/fstab,
что /dev/zram0 это вообще-то наша подкачка и установить ей
приоритет 100.
/etc/fstab# /dev/zram0 none swap defaults,pri=100 0 0
На этом все, теперь можно перезагружаться и проверять работу через
zramctl. Если такой способ для вас показался слишком сложным, то
обратитесь к использованию zram-generator как уже было показано
ранее.
Значение же vm.swappiness при использовании ZRAM рекомендуется
установить в 150, так как более низкие значения приведут к
излишнему вытеснению из файлового кэша, а анонимные страницы, которые
потенциально могут быть легко сжаты, будут вытесняться в последний
момент, что нежелательно. А вот при значении 150, файловый кэш
будет дольше оставаться нетронутым, благодаря чему обращения к ранее
открытым файлам останутся быстрыми, но при этом анонимные страницы
просто сожмутся внутри памяти. Такой подход минимизирует нагрузку на
ввод/вывод.
Отключение упреждающего чтения#
Из-за того, что процесс чтения вытесненной в подкачку страницы с диска и её записи обратно в оперативную память является довольно дорогостоящей операцией, ядро использует некоторые трюки, для того чтобы делать их как можно реже. Один из таких трюков это "упреждающее чтение" (readahead), когда при обращении процесса к вытесненной странице, ядро считывает не только запрошенную страницу, но и ещё некоторое количество страниц последовательно следующих за ней внутри подкачки.
Смысл здесь в том, что страница на практике это очень маленький фрагмент данных, которыми оперирует процесс, поэтому с большой долей вероятности обратившись к одной 4 Кб странице, процесс сделает ещё два и более запросов к тем страницам, которые тоже могли быть вытеснены в подкачку и быть записанными в него после той, которую процесс запрашивает в данный момент, и чтобы их потом тоже не искать и не читать ядро делает это сразу вместе с той вытесненной страницей, которую запросил процесс сейчас, так скажем, двух зайцев одним выстрелом.
Количество таких последовательно считываемых страниц за раз
контролируется значением параметра vm.page-cluster. Это значение
является степенью двойки, возведя в которую и можно получить
количество страниц. Например, если установлено значение 1, то
количество страниц, которые ядро считает заранее, будет равно 2^1, то
есть просто два. Если значение параметра равно 2, то количество
страниц уже будет равно в 2^2, то есть 4 и так далее. При значении
0 количество страниц будет 2^0, то есть 1 - это значение отключает
упреждающее чтение страниц из подкачки.
На первый взгляд всё звучит здорово, и надо бы выкрутить значение побольше, чтобы ядро читало больше страниц за раз, но есть одна маленькая проблема, из-за которой я настоятельно рекомендую отключать этот параметр. Дело в том, что ядро считывает из подкачки страницы, которые были записаны по порядку за той страницей, которая в данный момент запрошена для загрузки обратно в память. Мы подразумевали, что это будут страницы того же процесса, который запросил данную страницу, но на деле это может вообще не так. Ядро записывает страницы из памяти в подкачку в том порядке, в котором они были вытеснены, и они вообще не обязательно могут относится к одному и тому же процессу, а даже если к одному, то могут быть совсем не теми, которые процесс запросит в будущем. Короче говоря, с упреждающим чтением мы играем в своего рода рулетку, повезет или нет. Но в подавляющем большинстве случаев ядро просто вернет в память обратно ещё 8 страниц (согласно значению по умолчанию), которые могут никогда не пригодиться в будущем, а если они не пригодятся, то их придется опять вытеснять в подкачку.
Таким образом, упреждающее чтение не только не решает заявленную проблему, но и наоборот её усугубляет. Для ZRAM это, конечно, может и не так критично, так как это вызовет лишь дополнительные циклы сжатия/расжатия страниц, но это в любом случае холостая работа. По этой причине разработчики ChromeOS и Android отключают данный параметр в своих системах по умолчанию [14] [15], что советую сделать и вам. Для этого как обычно достаточно просто прописать значение в конфиге sysctl:
/etc/sysctl.d/99-sysctl.conf# vm.page-cluster = 0
Алгоритм MGLRU#
Мы уже говорили, что LRU - это алгоритм используемый ядром Linux для ведения учёта количества обращений ко всем страницам внутри памяти, позволяющий составлять выборку тех страниц, которые реже всего используются процессами и соответственно могут быть спокойно вытеснены в подкачку. Но начиная с версии 6.1 в ядре появилась альтернативная реализация этого алгоритма, называемая MGLRU (Multi-Generational LRU) [16]. Принципиальное отличие MGLRU от простого LRU алгоритма состоит в том, что выборка страниц, которые должны быть вытеснены, формируется не на основе только лишь одного признака (количества обращений к странице), а на основе целых двух признаков - количества обращений и времени последнего обращения. По этой причине новый алгоритм объединяет все страницы в так называемые "поколения" на основе времени обращения к ним, собственно именно поэтому его название и можно дословно перевести как "Многопоколенный LRU". Такой подход позволяет добиться большей точности в выборе из имеющихся страниц тех, которые по настоящему используются реже других, что в свою очередь позволяет уменьшать количество операций возврата страниц из подкачки, ибо чем точнее работает алгоритм выборки, тем больше вероятность, что вытесненная страница действительно никогда больше не понадобится и её не надо будет считывать с диска и загружать обратно в память.
Для того чтобы проверить собрана ли ваша версия ядра с поддержкой MGLRU достаточно прописать одну команду:
zgrep "CONFIG_LRU_GEN_ENABLED" /proc/config.gz
Если вывод команды не пустой, значит ваша текущая версия ядра собрана
с поддержкой данного алгоритма, но это вовсе не значит, что он
используется по умолчанию. Алгоритм MGLRU можно бесприпятственно
включить или выключить прямо во время работы системы. Проверить статус
работы алгоритма можно через файл /sys/kernel/mm/lru_gen/enabled:
cat /sys/kernel/mm/lru_gen/enabled
Если вывод команды равен 0x0000, значит MGLRU выключен, и его
нужно самостоятельно включить следующей командой:
echo "y" | sudo tee /sys/kernel/mm/lru_gen/enabled
Обратите внимание, что в большинстве дистрибутивов Linux версии ядра с поддержкой MGLRU поставляются по умолчанию, поэтому никаких дополнительных действий для его включения делать как правило не нужно.
Защита от Page Trashing#
Одним из преимуществ алгоритма MGLRU над своим предшественником является предоставление дополнительной защиты от ситуаций Page Trashing.
Page Trashing - это ситуация острой нехватки памяти, при которой памяти становится настолько мало, что ядро начинает вытеснять в подкачку даже те страницы, которые активно используются процессами во время своей работы, так как все остальные малоиспользуемые страницы уже были вытеснены. Это приводит к тому, что количество операций возврата страниц из подкачки многократно увеличивается, так как к данным часто используемым страницам все время обращаются процессы, из-за чего ядру приходится читать их из подкачки с диска или распаковывать их из памяти, если речь идёт про ZRAM, и заново загружать память, после чего снова их вытеснять, так как других кандидатов для этого больше не осталось. Такой цикл становится очень заметным для пользователя, так как он порождает кратковременные зависания системы, ибо процессу каждый раз приходится ожидать, пока ядро достанет страницы из подкачки и загрузит их обратно в память.
Конечно, если потребление памяти в этом случае продолжит расти, то мы столкнемся с ситуацией Out Of Memory (OOM), после чего либо специальный демон по наводке ядра убьёт самый прожорливый процесс, чтобы освободить память, либо система полностью зависнет. Если потребление останется тем же, то мы продолжим испытывать постоянные микрозависания, что не очень приятно.
Здесь на сцену выходит алгоритм MGLRU, который хоть и не позволяет на
100% защититься от таких ситуаций, но позволяет убрать те самые
кратковременные зависания, сделав систему более стрессоустойчивой и
отзывчивой в условиях нехватки ОЗУ. Суть защиты состоит в том, что
MGLRU предотвращает вытеснение "рабочего набора" страниц процесса (то
есть таких страниц, которые действительно активно используются) в
течении N миллисекунд, оставляя их не тронутыми в памяти на
протяжении по крайне мере этого гарантированного времени. В этом
случае процессам не придется каждый раз ожидать долгого восстановления
страниц из подкачки и они сохранят свою скорость работы, но с другой
стороны это увеличивает шанс возникновения ситуаций OOM, так как чем
больше разрастается такой "рабочий набор" страниц, тем больше
потребление памяти. По этой причине данный механизм защиты выключен по
умолчанию, так как возникновение OOM ситуаций часто нежелательно на
серверах и системах с большой нагрузкой, не предназначенных для
интерактивного использования, где такие небольшие зависания были бы
заметны глазу.
Для того чтобы включить данный механизм при использовании MGLRU нам
нужно изменить значение параметра min_ttl_ms (по умолчанию 0),
который как раз таки и устанавливает то время в миллисекундах, в
течении которого рабочий набор страниц не будет вытесняться. Автор
рекомендует брать значение от 1000 (это одна секунда), но не
большее 5000, ибо это приведет к более частому возникновению OOM.
Оптимальное значение для большинства - 2000 (2 секунды). В этом
случае система достаточно сохранит свою интерактивность под нагрузкой.
Указать значение можно как всегда через псевдофайловую систему sysfs,
для автоматизации процесса воспользуемся файлом конфигурации
systemd-tmpfiles:
/etc/tmpfiles.d/90-page-trashing.conf#w! /sys/kernel/mm/lru_gen/min_ttl_ms - - - - 2000
Настройка грязных страниц#
В теоретическом разделе про работу памяти в Linux мы уже говорили, что ядро отображает всю информацию об обычных файлах в виде кусочков - файловых страниц, при этом реальную память данная страница получает только непосредственно когда какая-то программа, то есть процесс начинает что-то читать или писать в файл, и если точнее, в определенное место внутри файла ассоциированное с данной страницей. Со чтением все понятно, мы просто сохраняем считанный набор байт с диска в память и многократно переиспользуем результат. Но что происходит в случае с записью?
Когда какой-то процесс начинает писать изменения в файл, то эти изменения сначала попадают в файловые страницы, но так как подразумевается, что проделанные изменения происходят с реальными файлами на диске, то перед ядром возникает задача синхронизации изменений между страничным кэшом и диском. С этой целью все измененные файловые страницы помечаются как "грязные" (dirty pages). Ядро ведет учёт таких страниц и в фоновом режиме, при определенных условиях, о которых пойдет речь далее, начинает "сбрасывать" такие страницы на диск, то есть записывать изменения над файлами уже по настоящему.
Смысл от такого буферизированного подхода состоит в том, чтобы минимизировать количество реальных операций записи, ибо приложения как правило большую часть времени не добавляют новые данные внутрь файла, а изменяют уже существующие и могут делать это много раз подряд в течение времени своей работы. Если приложение X изменяет 10 раз один и тот же файл в одном месте с малыми интервалами между такими операциями записи, то нет никакого смысла делать запись сразу же, ведь чем дольше ядро удерживает изменения внутри страничного кэша, тем больше уменьшает количество конечных, настоящих записей на диск, и вместо 10 операцией записи на диск мы можем получить одну запись уже итогового варианта изменений. Однако такой подход порождает и определенные риски, так как избыточное кэширование изменений внутри ОЗУ может привести к потери данных в случае отключения питания или непредвиденного зависания системы.
Стоит также отметить, что у приложений остается возможность выполнять
прямую запись в файл минуя страничный кэш. Первый способ это
использование Direct I/O (буквально: прямой ввод/вывод). Для его
применения приложению нужно установить специальный флаг при открытии
файла - O_DIRECT, после чего все операции над этим файлом будут
производиться в обход страничного кэша. Второй способ заключается в
том, чтобы использовать страничный кэш большую часть времени работы
программы, но форсировать его "промывку" (термин "промывка" (flush)
является антонимом к слову "грязный") в определенные моменты времени,
например при окончании работы с файлом или его сохранении в текстовом
редакторе. В этом случае приложение выполняет системные вызовы
sync() или fsync(), которые сигнализируют ядру о том, что
нужно в принудительном порядке записать все проделанные им изменения
из страничного кэша на диск.
Но вернемся к тому, как именно ядро сбрасывает грязные страницы на
диск. За это отвечают так называемые специальные ядерные потоки
pdflush, которые производят "промывку" грязных страниц в фоновом
режиме при соблюдении некоторых условий. Во-первых, данные потоки
начинают работать только тогда, когда набирается необходимый общий
объем грязных страниц, который устанавливается параметрами
vm.dirty_background_ratio или vm.dirty_background_bytes. До
тех пор пока указанная нижняя граница не будет достигнута, изменения
внутри грязных страниц так и будут оставаться в ОЗУ, за тем
исключением, если, как и было указано выше, процесс явно не попросит
записать на диск изменения через вызовы sync() или fsync().
При этом важно отметить, что если страница была изменена процессом, то
при штатной работе потоков pdflush без принудительной промывки со
стороны самого приложения, страница становится готовой к записи не
сразу же, а только по истечению времени указанного в качестве значения
параметра vm.dirty_expire_centisecs, которое представлено в виде
сантисекунд (одна сотая от секунды) и по умолчанию равно 3000 [4]
(30 секунд).
После запуска потоков pdflush их работа происходит не непрерывно
как можно было бы подумать, а с интервалами между которыми они
просыпаются и выполняют часть работы. Время этих промежутков
определяется значением параметра vm.dirty_writeback_centisecs, так
же принимающего значение в виде сантисекунд и равного по умолчанию
500 [4], то есть 5 секунд, что весьма много, но это гарантирует,
что потоки pdflush не будут создавать чрезмерной нагрузки.
Наконец, существует также верхняя граница, которая определяет
максимально возможный объем грязных страниц. Она определяется
значением параметра vm.dirty_ratio, либо vm.dirty_bytes. Если
к тому времени, когда потоки pdflush начали свою работу, объем
грязных страниц продолжал увеличиваться с такой скоростью, что ядро
просто не успевало записать все поступающие изменения на диск, то
возникает так называемый "троттлинг" ввода/вывода.
В старых версиях ядра "троттлинг" ввода/вывода проявлялся только
непосредственно по достижению верхней границы количества грязных
страниц, и приводил к полной блокировке всех операций ввода/вывода до
тех пор пока потоки pdflush полностью не запишут уже накопленные
ранее изменения на диск. Это приводило к очень печальным последствиям,
в том числе известный баг в ядре 12309 был связан
именно с тем, что интенсивная запись каким-либо процессом на носитель
с очень низкой скоростью (вроде простой USB флешки) приводила к ярко
выраженным зависаниям всей системы, так как операции I/O
блокировались, а фоновые потоки pdflush не могли быстро записать
изменения в силу аппаратных ограничений самого носителя.
В новых версиях ядра были предприняты большие усилия к исправлению
данной проблемы [17], и в конце концов было принято решение, которое можно
охарактеризовать как "размывание" процесса троттлинга во времени. То
есть, когда текущий объем грязных страниц начинает быть равным
примерно 1/2 между значениями vm.dirty_background_bytes (или
vm.dirty_background_ratio) и vm.dirty_bytes (или
vm.dirty_ratio), то есть между нижней и верхней границей
соответственно, то тогда ядро начинает постепенно создать
кратковременные паузы (блокировки) в работе ввода/вывода для процесса,
в результате работы которого появляется большое количество грязных
страниц, так чтобы потоки pdflush успевали обработать уже
накопленные грязные страницы. Такие палки в колеса активно пишущему
процессу закономерно приводят к падению пропускной способности записи,
но позволяют избавиться от эффекта "голодания", когда один процесс
полностью оккупирует всю квоту на грязные страницы, не позволяя ничего
писать другим процессам, а также от полных блокировок ввода/вывода,
так как в случае достижения верхней границы ядро просто тормозит
работу ввода/вывода для процесса таким образом, чтобы потоки
pdflush гарантированно могли записать все полученные грязные
страницы до снятия блокировки, как правило тем самым уравнивая
скорость записи грязных страниц приложением со скоростью записи
потоков pdflush [18], [19].
Учитывая количество параметров, контролирующих поведение грязных
страниц и факторов, оказывающих влияние на их работу, возникает вполне
закономерный вопрос о том, как это настроить оптимальным образом для
своей конфигурации и задач? Для начала, как вы уже могли заметить,
существует некоторая двойственность в вопросе указания нижней и
верхней границы работы потоков pdflush, так для их настройки
существует две пары настроек vm.dirty_background_bytes и
vm.dirty_bytes или vm.dirty_background_ratio и
vm.dirty_ratio. Несмотря на то, что обе пары
контроллируют по сути одно и то же, они конфликтуют друг с другом, то
есть указать можно только один из пары, так как указание одного
отменяет значение другого. Кроме того существует некоторая разница в
их семантике. Все параметры с окончанием ratio указывают процент
от свободной в данный момент памяти, который могут занимать грязные
страницы вообще (в случае с vm.dirty_ratio) или же пороговое
значение для начала работы потоков pdflush
(vm.dirty_background_ratio). Частое заблуждение относительно этой
пары параметров состоит в том, что процент берется от общего
количества памяти в целом, а не от свободной, что приводит к
неправильным умозаключения о выборе значения в зависимости от объема
памяти.
В целом, по мнению автора, использование параметров vm.dirty_ratio
и vm.dirty_background_ratio нежелательно, так как их поведение не
является строго фиксированным и объем грязных страниц таким образом
находится в обратной пропорциональной зависимости по отношению к
текущему уровню потребления памяти, который склонен к тенденции
увеличения в процессе работы системы больше, чем к уменьшению. Скажем,
мы можем взять 2% от 32 Гб в качестве значения к параметру
vm.dirty_ratio. Если в моменте вся память свободна (что, конечно,
в действительности невозможно), мы получаем максимальный объем грязных
страниц равный примерно 678 Мб, что на первый взгляд много, но
среднестатический пользователь гораздо чаще открывает новые вкладки в
браузере или открывает новые приложения, чем их закрывает, поэтому
легко представить ситуацию, когда даже с 32 Гб ОЗУ вы достигаете
уровня потребления 28 Гб ОЗУ, к примеру, компилируя что-то внутри
tmpfs, и в этом случае объем грязных уже будет составлять всего 85 Мб
и дальше ещё больше уменьшаться. То есть, по существу использование
параметров с окончанием ratio приводит к тому, что большую часть
времени работы системы объем грязных страниц представляет собой
убывающую геометрическую прогрессию. В то же время другая пара
параметров, vm.dirty_bytes и vm.dirty_background_bytes, не
имеет такой зависимости [20] и позволяет однозначно определить порог
грязных страниц для начала работы потоков pdflush и установить
максимально возможный объем грязных страниц вне зависимости от
текущего уровня потребления памяти.
Сами же значения к vm.dirty_bytes и vm.dirty_background_bytes
следует выбирать в зависимости от ваших целей и задач, но для
домашнего использования в качестве vm.dirty_bytes разумно брать
тот объем данных, который ваш основной носитель может обработать за
единицу времени, то есть его пропускную способность, так как тогда
даже в худшем случае указанный объем грязных страниц может быть
записан достаточно быстро. Значение же vm.dirty_background_bytes
как правило лучше делать равным 1/2 или даже 1/4 от значения
vm.dirty_bytes, так как чем больше "расстояние" между порогом к
запуску потоков pdflush и максимальным объемом грязных страниц,
тем меньше вероятность столкнутся с эффектом троттлинга и падением
пропускной способности записи. Так же слишком завышенное значение
vm.dirty_background_bytes черевато "застоем" данных внутри ОЗУ,
что сулит риски их потери при отключении питания или зависаниях
системы. Нужно понимать, что сверхвысокие значения просто не имеют
смысла при простом домашнем использовании, так как рядовой
пользователь не имеет приложений, которые могли бы иметь большую
интенсивность записи данных на диск, как например СУБД. Как правило
самыми интенсивными приложениями с точки зрения записи остаются
торрент клиенты, Steam, и другие программы для загрузки контента,
однако объем данных, который они записывают на диск ограничен
пропускной способностью вашего сетевого канала, который у большинства
людей хоть и чисто номинально составляет 100 Мб/c, однако в ряде
случаев оказывается куда ниже, так что сверх большие объемы грязных
страниц указывать просто нет смысла. В качестве начальных значений, на
которые можно было бы опереться, автор рекомендует взять 32 или 64 Мб в
качестве dirty_background_bytes и 256 Мб в качестве
dirty_bytes:
/etc/sysctl.d/30-dirty-pages.conf#vm.dirty_background_bytes=67108864
vm.dirty_bytes=268435456
Вы вправе кратно уменьшить значение параметра vm.dirty_bytes,
если у вас медленный HDD, или же наоборот увеличить вплоть до 1-2 Гб,
если имеете сверхбыстрый носитель и высокую скорость передачи данных
по сети.
Что касается значений параметров vm.dirty_expire_centisecs и
vm.dirty_writeback_centisecs, которые управляют частотой работы
pdflush потоков, то вы могли заметить, что значения по умолчанию
сильно завышены. Ожидать 30 секунд, как предписывает значение по
умолчанию параметра vm.dirty_expire_centisecs, перед тем чтобы
позволить записывать pdflush новую грязную страницу кажется
чрезмерным, поэтому разумно уменьшить значение данного параметра вдвое,
то есть сократить период ожидания до 15 секунд, либо же ещё
меньше, но устанавливать сверх низкие значения вроде 1-3 секунд также
не рекомендуется, так как это может свести на нет все преимущества
кэширования при записи. Оптимальным, по мнению автора, является
значение в 15 секунд, то есть значение 1500 при переводе в
сантисекунды:
/etc/sysctl.d/30-dirty-pages-expire.conf#vm.dirty_expire_centisecs=1500
Интервал времени между периодами работы потоков pdflush
определяемый параметром vm.dirty_writeback_centisecs так же можно
уменьшить, так как современные SSD носители достаточно хорошо
справляются с интенсивной нагрузкой, поэтому можно увеличить частоту
работы pdflush потоков и таким образом ещё больше уменьшить шансы
на столкновение с эффектом троттлинга при записи:
/etc/sysctl.d/30-dirty-pages-writeback.conf#vm.dirty_writeback_centisecs=100
Настройка кэша VFS#
В страничный кэш попадают не только файловые страницы, в которых хранятся непосредственно данные считываемые с диска, но и метаданные к файлам и директориям. Доступ к ним осуществляется через так называемые индексные дескрипторы (inode) - специальные структуры, которые используются вашей файловой системой для хранения атрибутов, прав доступа и прочей служебной информации, а также они содержат номера секторов диска, которые указывают, где хранятся данные самого файла на носителе.
Перед открытием любого файла или дириктории сначала нужно выполнить его поиск на файловой системе, и это не самая быстрая операция как может показаться, даже несмотря на различные оптимизации, предоставляемые современными файловыми системами такими как использование B-деревьев для быстрого прохода по ним. В результате этой операции ядро как раз таки находит нужный индексный дескриптор, имея который можно обратиться к данным файла. Поэтому ядро кэширует все используемые во время работы системы дескрипторы и информацию о директориях внутри VFS [21] кэша, для того чтобы сделать все последующие обращения к файлам быстрыми, потому что ядро уже будет знать про них всё, что нужно.
Но все эти метаданные так или иначе занимают место внутри памяти,
поэтому когда ядро начинает "промывку" (flush) страничного кэша, то
оно вытесняет из него как данные самих файлов, так и метаданные для
них. В ядре также есть специальный параметр sysctl
vm.vfs_cache_pressure, который как раз таки регулирует, что будет
вытесняться в первую очередь - сами данные или метаданные из кэша VFS.
Здесь всё по аналогии с параметром vm.swappiness. При значении
равном 100 (значение по умолчанию) ядро будет пытаться равномерно
выгружать из памяти как кусочки содержимого самих файлов, так и
индексные дескрипторы из кэша VFS. При значениях меньше 100 ядро
будет больше отдавать предпочтение хранению метаданных в памяти, при
значениях больше 100 - наоборот, больше избавляться от них в
пользу обычных данных считываемых с диска.
Для наилучшего быстродействия системы рекомендуется устанавливать
значение равным 50 [22], при котором вытеснение страниц,
относящихся к VFS кэшу, происходит реже, чем для обычных файловых
страниц, так как метаданные имеют большую ценность по сравнению с
данными самих файлов, которые можно достаточно быстро повторно считать
в страничный кэш на большинстве SSD накопителей при наличии индексного
дескриптора файла, который как раз таки хранится внутри VFS кэша. Для
сохранения значения как и всегда пропишем его в конфигурационный файл
sysctl:
/etc/sysctl.d/90-vfs-cache.conf#vm.vfs_cache_pressure = 50
Конечно, лучший способ увеличения быстродействия ввод/вывода это
кэшировать как можно больше данных в памяти, так как это самое быстрое
устройство хранения в вашем компьютере (без учета кэша процессора),
поэтому лучше всего как можно больше минимизировать вытеснение страниц
из страничного кэша, но мы это уже сделали в разделе про настройку
подкачки, установив большое значение параметра vm.swappiness и
используя ZRAM для сжатия анонимных страниц прямо внутри памяти.
Настройка планировщиков ввода/вывода#
Планировщики ввода/вывода - это специальные модули ядра, которые регулируют порядок выполнения операций ввода/вывода во времени на уровне обращения к блочным устройстам (HDD дискам или SSD/NVMe/microSD/SD накопителям). Если вам казалось, что все запросы на чтение или запись происходят сразу же, то это не так.
Все запросы к носителю сначала попадают в очередь, которой и управляет
планировщик ввода/вывода. В зависимости от используемого алгоритма он
"ранжирует" все поступающие запросы таким образом, чтобы запросы
которые осуществляются к соседним блокам на диске шли как бы друг за
другом, а не в том порядке в котором они поступили в очередь. К
примеру, если к планировщику поступили запросы на чтение 9, 3
и 5 блоков (условная запись), то он попытается разместить их в
очереди как 3, 5 и 9. Зачем это делается? В силу
исторических причин, все планировщики изначально разрабатывались с
целью нивелировать недостатки механических дисков (и HDD в том числе),
которые в силу своей специфики работы были чувствительны к порядку
осуществления любых операций чтения или записи, так как чтобы
выполнить любую операцию головке жесткого диска нужно было сначала
найти нужный блок, а когда головка сначала выполняет чтение блока
9, а потом чтение "назад" блока 3, чтобы потом опять
переместить головку вперед на блок 5, то очевидно что это
несколько уменьшает пропускную способность диска.
Поэтому все планировщики и работают по принципу "лифта" (elevator): когда планировщик добавляет все запросы в очередь, но при этом планирует их выполнение уже в порядке возрастания по номерам блоков, к которым они обращаются. Кроме того, планировщик всегда будет отдавать предпочтение запросам на чтение запросам на запись, в силу того, что выполнение запросов на запись может быть неявно отложено ядром, либо происходит куда быстрее в силу того, что запись сначала осуществляется в страничный кэш (то есть в ОЗУ), а только потом на диск. В случае с операциями чтения их выполнение не может быть отложено, банально в силу того, что все программы, которые читают файлы, явно ожидают получения какого-то результата.
Конечно, на деле алгоритм планирования запросов ввода/вывода куда
сложнее, но общий принцип остается тем же. На текущий момент в ядре
существует три "реальных" планировщика ввода/вывода: BFQ,
mq-deadline, kyber. Существует также четвертый вариант
none, который устанавливает простую FIFO очередь для всех
запросов. Это значит, что они будут обрабатываться ровно в том
порядке, в котором поступили без какого-либо планирования.
Хотя выбор не велик, выбор планировщика может сильно зависеть от типа используемого носителя. Общие рекомендации к выбору планировщика под определенный тип носителя состоят в следующем:
Для NVMe и SATA SSD накопителей используйте
none. Дело в том, что вся вышеописанная логика нахождения нужных блоков с использованием головки совершенно не актуальна для твердотельных накопителей с быстрым произвольным доступом [23], где любое обращение к блокам осуществляется за фиксированное время, поэтому порядок выполнения запросов для них не имеет такого же значения как для жёстких дисков. В то же время, накладные расходы при планировании прямо пропорциональны количеству запросов в очереди, которые планировщику нужно обработать ресурсами CPU, но в NVMe и простых SSD носителях планированием поступающих запросов на аппаратном уровне уже занимается встроенный контроллер, поэтому планировщик в ядре Linux по сути работает в холостую [24], нагружая при этом процессор, что в свою очередь может вызывать кратковременные зависания системы при большой нагрузке на ввод/вывод.Однако для SATA SSD с плохим контроллером или устаревшим интерфейсом подключения (SATA 2) имеет смысл использовать планировщик
mq-deadline. Для SD/microSD карт так же имеет смысл использовать только mq-deadline.Для HDD следует использовать BFQ, но в целом любой планировщик должен быть лучше, чем его отсутствие как уже объяснено выше.
Как вы видите, здесь мы проигнорировали планировщик Kyber по той причине, что он практически не развивается за последние 3 года (то есть не получает новых значимых улучшений/оптимизаций) и рассчитан на работу со сверх быстрыми накопителями, которые чувствительны к задержкам, что не совсем актуально для домашней системы.
Итак, теория это хорошо, но как их все таки включить? Самый
универсальный способ это написать собственные правила Udev, которые
могли бы автоматически выбирать нужный планировщик в зависимости от
типа носителя. Чтобы создать новые правила просто создадим
новый файл в /etc/udev/rules.d/90-io-schedulers.rules:
/etc/udev/rules.d/90-io-schedulers.rules## HDD
ACTION=="add|change", KERNEL=="sd[a-z]*", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="bfq"
# eMMC/SD/microSD cards
ACTION=="add|change", KERNEL=="mmcblk[0-9]*", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="mq-deadline"
# SSD
ACTION=="add|change", KERNEL=="sd[a-z]*", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="none"
# NVMe SSD
ACTION=="add|change", KERNEL=="nvme[0-9]*", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="none"
(Чтобы использовать планировщик mq-deadline для SATA SSD просто
поменяйте значение внутри кавычек в третьей строке с none на
mq-deadline).
Помните, что универсального рецепта не существует, и всегда следует выполнить собственные тесты и бенчмарки (например при помощи программы KDiskMark), чтобы понять какой из планировщиков вам подходит лучше.
Увеличение размера карты памяти процесса#
Так как виртуальные страницы процесса представляют собой кучу
маленьких фрагментов его данных, то для удобства вся его виртуальная
память разграничивается ядром на зоны. Например, в одной зоне памяти
процесса может быть загружена библиотека libc.so.6, а в других
зонах - бинарный код другой библиотеки или данные самой программы,
память под которые она запросила у ядра через функцию mmap. Зон
может быть несколько, так как они различаются по своим правам доступа
(Да, права есть не только у файлов, но и у виртуальных страниц).
Информация об этих зонах памяти процесса ядро хранит в так называемой
виртуальной карте памяти (memory map). Здесь речь идёт вовсе не о
носителе данных, а о той карте, которая используются ядром для того
чтобы понимать, начиная с какого адреса в памяти процесса расположена
та или иная зона. Вы можете просмотреть эту карту прочитав файл
maps на псевдофайловой системе procfs в директории, которая
предоставляет информацию о процессе с соответствующим ID.
Размер таких карт у каждого процесса ограничен значением параметра
vm.max_map_count , которое указывает на максимальное количество
записей, которое может хранится в карте у процесса. По умолчанию это
значение равно 65530 [4]. К сожалению, современные программы, в
особенности игры запускаемые через Wine/Proton, с их потреблением
более 8 Гб на процесс, могут запрашивать чрезмерно много виртуальных
страниц у ядра, из-за чего количество зон для их процессов начинает
превышать установленный лимит по умолчанию. Это приводит к тому, что
ядро просто не даёт выделить ещё одну зону в памяти у процесса, что в
свою очередь приводит к проблемам со стабильностью (приложение может
просто аварийно завершится) и производительностью в таких прожорливых
программах. Поэтому если вы столкнулись с неполадками во время игры,
такими как частые вылеты или микрофризы, не спишите сразу писать
гневные письма разработчикам Wine, а попробуйте увеличить значение
данного параметра.
Чтобы избежать всех этих потенциальных проблем, рекомендуется
увеличить допустимый размер карты памяти процесса, то есть значение
параметра sysctl vm_max_map_count до 1048576. Тогда памяти
хватит точно всем :)
/etc/sysctl.d/99-sysctl.conf#vm.max_map_count = 1048576
Отключение многоступенчатого включения дисков#
Для классических жестких дисков и иных носителей, подключаемых через интерфейс SATA, существует механизм по многоступенчатому включению питания, называемый Staggered spin-up (сокращенно - SSU), суть которого состоит в том, что питание всех носителей у вас в системе включается последовательно. То есть сначала начинает свою работу диск №1, потом диск №2 и так далее. SSU был разработан и включен в спецификацию SATA 2.5 достаточно давно - в 2005 году, когда компьютеры были слишком слабыми и не выдерживали одновременного включения всех дисков при загрузке системы.
В современных реалиях никакой необходимости в использовании SSU больше нет, так как современные блоки питания спокойно выдерживают пиковое энергопотребление, вызванное включением 3-4х и более носителей одновременно, каждый из которых как правило имеет пиковую нагрузку всего в 5W-12W [27], в то же время использование SSU по умолчанию приводит к снижению скорости загрузки системы, поэтому он однозначно рекомендуется к отключению на всех современных системах, если вы имеете блок питания, который покрывает потребление вашего железа не "впритык", а хотя бы с небольшим запасом.
В Linux это можно сделать через использование параметра
ignore_sss=1 для модуля ядра libahci, отвечающего за
реализацию общих функций по управлению всеми ATA устройствами. Для
этого следует создать новый файл в директории /etc/modprobe.d:
/etc/modprobe.d/30-ahci-disable-sss.conf#options libahci ignore_sss=1
После этого на системах под управлением дистрибутива Arch Linux или
другого, основанного на нем, требуется также выполнить обновление
образов initramfs, чтобы данная конфигурация для modprobe стала их
частью и была применена на этапе ранней загрузки системы:
sudo mkinitcpio -P
Примечание
Вы можете пропустить шаги из данного раздел, если имеете всего один жесткий носитель или не имеете их вообще, так как данный параметр не оказывает влияния на устройства, подключенные не через SATA.
Дедупликация страниц памяти#
KSM (Kernel Samepage Merging) - механизма ядра Linux, который
позволяет экономить использование памяти путём поиска страниц с
одинаковым содержимым и их объединения в виде единичного экземпляра
[28]. Работа по поиску "дубликатов" реализована при помощи фонового
демона в ядре, называемого ksmd, который проходится по
pages_to_scan страниц (по умолчанию 100), помеченных для
поиска, раз в sleep_millisecs миллисекунд (по умолчанию 20).
Так как определение уникальности содержимого каждой страницы вполне
естественно привносит некоторую нагрузку с использованием CPU, то
изменение значений данных параметров (расположенных в
/sys/kernel/mm/ksm) позволяет при необходимости минимизировать
накладные расходы.
По умолчанию ksmd не работает и его нужно активировать вручную при
помощи следующей команды:
echo 1 | sudo tee /sys/kernel/mm/ksm/run
Для активирования же при запуске системы можно создать файл в
директории /etc/tmpfiles.d со следующим содержимым:
/etc/tmpfiles.d/ksm.conf#w! /sys/kernel/mm/ksm/run - - - - 1
Также нужно указать диапозон страниц, в которых следует осуществлять
поиск дупликатов. Ранее это можно было сделать только при помощи
системного вызова madvise(), в качестве параметров которого
программа должна была указать начальный адрес и длину поиска. Однако с
версии ядра 6.4 появился и упрощенный способ маркировки при помощи
системного вызова prctl() со значением PR_SET_MEMORY_MERGE,
что сразу помечает область для сканирования не только определенно
выбранного региона, но и память всего процесса целиком [29].
Преимуществом данного способа является то, что данный атрибут
наследуется процессами при ветвлении, то есть память всех дочерних
процессов так же будет учитываться ksmd при поиске дубликатов.
В связи с этим, начиная с версии v254 systemd позволяет выборочно
включать использование KSM для запускаемых с его помощью служб
используя опцию MemoryKSM=yes [30], но так как системный менеджер
по сути является прародителем всех процессов в системе (будучи PID 1),
то ничего не мешает распространить действие KSM к примеру и на все
пользовательские процессы путём создания соответствующего
конфигурационного файла:
/etc/systemd/system/user@.service.d/10-ksm.conf#[Service]
MemoryKSM=yes
После сохранения изменений и перезапуска системы проверить корректность применения атрибута можно при помощи специальной программы, исходный код которой приложен ниже:
/tmp/ksmtest.c##include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/prctl.h>
int main() {
prctl(PR_SET_NAME, "example");
printf("PID: %d, Name: %s\n", getpid(), "example");
int status = prctl(PR_GET_MEMORY_MERGE, 0, 0, 0, 0);
printf("KSM Status: %s\n", (status == 1 ? "Enabled" : "Disabled"));
return 0;
}
Скомпилировав и запустив данную программу можно понять распространяется ли работа KSM для пользовательских процессов:
gcc -o /tmp/ksmtest /tmp/ksmtest.c
./ksmtest
Если вывод команды следующий:
PID: 7072, Name: example
KSM Status: Enabled
То всё работает и можно получить статистику о текущем общем объеме сэкономленной памяти в мегабайтах при помощи следующей команды:
awk '{ print($0 / 1024 / 1024) }' /sys/kernel/mm/ksm/general_profit
Следует иметь в виду, что в целях оптимизации своей работы ksmd
ещё и ведет учёт об уже пройденных страницах в специальную структуру
rmap_items, каждая запись внутри которой тоже занимает некоторое
количество памяти, поэтому общий объем "выигрыша" считается как:
general_profit =~ ksm_saved_pages * sizeof(page) - (all_rmap_items) *
sizeof(rmap_item);
То есть количество дедублицированных страниц умноженное на размер
одной страницы минус количество записей внутри структуры
rmap_items на размер одной записи. По этой причине использование
KSM иногда наоборот может приводить к увеличению потребления памяти -
в случае, когда все страницы процесса являются уникальными,
rmap-записи расходуют лишнюю память, хотя и их объем не велик (для
x86-64 архитектуры - всего 64 байта на одну страницу), но это может
привести вас к желанию использовать механизм KSM более "точечным"
образом, только для определенного перечня процессов, что достижимо
средствами того же systemd через команду systemd-run. На примере
той же проверочной программы ksmtest запустим её как
"кратковременный" юнит:
systemd-run --user \
--pty \
--same-dir \
--wait \
--collect \
-p MemoryKSM=yes \
/tmp/ksmtest
Вывод должен остаться таким же, как и в случае с глобальным применением KSM. В целом же использование данного механизма рекомендуется в программах связанных с обработкой большого количества произвольных пользовательских данных, которые часто содержат чрезмерно много повторяющихся элементов. Примерами можно назвать: браузеры (и основанные на их движках приложения), виртуальные машины и даже видеоигры.
Оптимизация работы CPU#
Нельзя прямо или косвенно улучшить характеристики вашего процессора, однако можно использовать более эффективное и отвечающее вашим задачам планирование работы процессов, а также отключить некоторые лишние возможности ядра, которые могут приносить больше вреда, чем пользы для простого пользователя. В этом разделе пойдет речь о том, как добиться более эффективного использования ресурсов вашего "камня" с целью получить более хорошую производительность.
Масштабирование частоты CPU#
В Linux существует специальные модули ядра, так называемые драйверы
масштабирования CPU. Они корректируют частоту вашего процессора в
режиме реального времени в зависимости от используемой политики
(governor) масштабирования частот процессора. Для x86 архитектуры
стандартным таким драйвером в ядре Linux принято считать
acpi-cpufreq, который, как понятно из названия, осуществляет
регулировку путем специальных вызовов APCI, которые устанавливают так
называемый P-state (Peformance state) уровень для вашего процессора.
Уровни P-State вашего процессора можно сравнить с коробкой передач у
автомобиля: он может лететь на всей скорости, ехать с обычной
автомобиля: он может лететь на всей скорости, ехать с обычной
скоростью, и стоять на месте в ожидании того, когда надо будет
сдвинуться с места. Собственно, по этой аналогии acpi-cpufreq и
переключается между 3-х стандартных P-State уровней в зависимости от
используемой политики масштабирования.
Политики масштабирования частоты#
Вернемся к политикам масштабирования частоты. Их можно сравнить с
планами электропитания в настройках Windows, только в отличии от них
политик масштабирования в Linux довольно много: performance,
powersave, userspace, ondemand,
conservative, schedutil.
Рассмотрим каждую из них подробнее:
performance - как понятно из названия, данная политика
используется для достижения максимальной производительности, так как
она сильно снижает порог нагрузки, переходя через который процессор
начинает работать на полную мощность. Хорошо подходит для настольных
ПК, но не слишком желательно для использования на ноутбуках, где важна
автономность. Обратите внимание, что поведение данной политики зависит
от используемого драйвера масштабирования, об этом подробнее читайте
далее в разделе Альтернативные драйверы масштабирования.
powersave - полная противоположность performance, минимизирует
потребление энергии через занижение частот процессора до минимума.
Может быть очень полезно для ноутбуков при работе от батареи. Обратите
внимание, что поведение данной политики зависит от используемого
драйвера масштабирования, об этом подробнее читайте далее в разделе
Альтернативные драйверы масштабирования.
ondemand - политика, которая регулирует частоту процессора на
основе общей нагрузки на процессор, то есть частота прямо
пропорциональна нагрузке: Чем выше нагрузка, тем больше частота, и
наоборот, чем ниже, тем ниже и частота. Конечно, скорость возрастания
частоты и нагрузки не всегда коррелируют между собой, ибо для принятия
решения о том, когда нужно повышать частоту до максимальных значений,
драйвер руководствуется значением параметра up_threshold (по
умолчанию 80%), которое устанавливает порог максимальной нагрузки в
процентах, которое должно достичь хотя бы одно из ядер вашего
процессора. К примеру, если у вас есть два ядра, и в текущий момент
времени драйвер масштабирования зафиксировал на одном ядре процессора
нагрузку в 70%, а на другом в 81%, то он станет повышать их частоты в
соответствии со значением up_threshold по умолчанию. Обратное
решение - понижение частоты CPU, драйвер принимает в соответствии со
значением другого параметра - down_threshold, которое также
устанавливает порог ниже которого должно пройти хотя бы одно ядро
процессора, тогда частота будет понижена. Во всех остальных случаях
частота будет регулироваться как обычно, то есть пропорционально общей
нагрузке.
Довольно хороший выбор для большинства конфигураций и задач. Рекомендуется к использованию.
conservative - должно быть вы замечали, как запуская игру или
"тяжёлое" приложение ваш компьютер или ноутбук начинает гудеть как
самолет, так как происходит резкое повышение частот процессора и
следовательно растет его температура. conservative очень похож на
политику ondemand, но он делает процесс увеличения частоты CPU
более "гладким" и поступательным даже при значительном повышении
нагрузки. Это может быть очень полезным, когда вы не хотите чтобы ваш
ноутбук резко повышал свою температуру или уходил в так называемый
"турбобуст".
schedutil - регулирует частоту процессора на основе метрик
планировщика CPU, например таких как количество активных процессов на
ядро процессора. Не слишком рекомендуется в силу того, что
использование данной политики часто приводит к резким скачкам частоты
без необходимости. Несмотря на это, данная политика используется по
умолчанию в стандартном ядре Arch Linux.
userspace - данная политика является заглушкой, которая позволяет
передать полномочия управления частотой с драйвера масштабирования на
программу, запущенную с правами root, в пространстве пользователя,
которая и будет осуществлять процесс регулировки частоты в
соответствии с собственной логикой. В большинстве случаев вам никогда
не понадобиться эта политика.
Альтернативные драйверы масштабирования#
Современные процессоры Intel и AMD могут самостоятельно осуществлять масштабирование своей частоты на основе информации получаемой через механизм CPPC (Collaborative Processor Performance Control), с которым процессор получает от драйвера масштабирования "подсказку", о том какой уровень производительности следует выдавать в данный момент. Специально для работы с этим механизмом были созданы драйверы amd-pstate (поддерживается процессорами Zen 2 и выше) и intel-pstate (поддерживается Sandy Bridge и выше) для процессоров AMD и Intel соответственно.
Примечание
Для процессоров Intel термин CPPC обычно не используется, так как их технология для автономного управления частотой процессора называется HWP (Hardware P-states), но суть остается той же, что и в случае с CPPC.
У драйверов P-state существует несколько режимов работы. Как для
intel-pstate, так и для amd-pstate есть active и passive
режим, но для amd-pstate есть также guided режим.
В режиме active, который используется по умолчанию во всех P-state
драйверах, управление частотой выполняется полностью автономно самим
процессором, но он получает от драйвера масштабирования "подсказку" -
так называемый уровень energy_performance_preference (далее EPP),
на основе которого процессор понимает с каким уклоном ему регулировать
собственную частоту. Таких уровней всего пять: power,
balance_power, default, balance_performance,
performance. Как понятно из названия, эти уровни указывают
процессору предпочтение к тому, чтобы он работал на максимальную
мощность (при использовании уровней balance_performance и
performance) или наоборот экономил энергию и чаще принимал решение
о понижении своей частоты или уходе в состояние сна. По умолчанию
используется default, что представляет собой баланс между
максимальной производительностью и энергосбережением.
Важно отметить, что классические политики для управления частоты,
которые мы описывали ранее, отходят на второй план, и более того, в
режиме active вы сможете выбрать всего две "фиктивные" политики
масштабирования, это powersave и performance. Обе из них не
оказывают того влияния на частоту процессора, которое мы приписывали
им ранее, так как в режиме active драйвер не может самостоятельно
устанавливать частоту процессора и теперь это зависит только от
используемого значения EPP. Поэтому при выборе performance
политики вы на самом деле просто измените текущий уровень EPP на
performance, значение которого P-state драйвер передаст процессору
через специальный регистр. Но при переключении политики на
powersave уровень EPP не измениться и вы должны будете установить
его самостоятельно (об этом читайте далее).
При использовании режима passive P-State драйвер может напрямую
устанавливать желаемый уровень производительности, в связи с чем в нем
доступен полный набор политик масштабирования, о которых мы говорили
ранее. При этом установить уровень EPP становится невозможно, так как
процессор уже не управляет частотой полностью самостоятельно, а
ожидает переключения уровня P-State со стороны драйвера
масштабирования. Данный режим отличается от использования
классического драйвера acpi-cpufreq тем, что драйвер переключается
не между 3-мя уровнями P-State, которые определены стандартом ACPI, а
между сразу всеми доступными диапазонами частоты для вашего
процессора, что гораздо эффективнее.
Для драйвера amd-pstate существует также третий режим работы -
guided. Он работает аналогично режиму active, позволяя
процессору самому управлять частотой, но при этом драйвер может
устанавливать процессору пороги минимальной и максимальной частоты,
что позволяет использовать классические политики масштабирования как в
случае с passive режимом.
Переключение между всеми тремя режимами может быть осуществлено как
при помощи соответствующих параметров ядра amd_pstate (например,
amd_pstate=guided) или intel_pstate в зависимости от
используемого драйвера масштабирования, так и прямо во время работы
системы при помощи файла status на псевдофайловой системе sysfs:
echo "passive" | sudo tee /sys/devices/system/cpu/amd_pstate/status
sudo cpupower set --amd-pstate-mode passive
echo "passive" | sudo tee /sys/devices/system/cpu/intel_pstate/status
Настройка параметров масштабирования#
Перейдем от теории к практике. Чтобы изменить текущую политику
масштабирования частоты можно воспользоваться множеством различных
способов, начиная от способа "руками" при помощи sysfs, заканчивая
специализированными утилитами как cpupower и
power-profiles-daemon, которые мы и будем использовать для
удобства. Для начала установим программу cpupower:
sudo pacman -S cpupower
С её помощью мы можем быстро увидеть информацию о текущей политике масштабирования, используемом драйвере, а также текущую частоту:
cpupower frequency-info
Установить желаемую политику масштабирования можно через команду
frequency-set. К примеру, установим политику performance:
sudo cpupower frequency-set -g performance
Примечание
Если команда cpupower frequency-info указывает на то,
что используется P-State драйвер в автономном режиме, то не следует
пытаться применять классические политики масштабирования, вместо
этого нужно указывать значение параметра
energy_performance_preference (EPP) при помощи команды
cpupower set --epp, например:
sudo cpupower set --epp balance_performance
Узнать доступные значения параметра EPP можно через:
cat /sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences
Это значение будет той самой подсказкой для процессора, о которой мы говорили выше, в соответствии с которой он будет осуществлять самостоятельный контроль своей частоты.
Если вы хотите ограничить максимальную частоту процессора, то вы
можете использовать ключ -u:
# Ограничит максимальную частоту в 3 ГГц
sudo cpupower frequency-set -u 3.0Ghz
Все проделанные изменения выше работают только до перезагрузки
системы, чтобы их сохранить нам понадобиться одноименный демон
cpupower.service:
sudo systemctl enable --now cpupower
А также изменить конфигурацию /etc/default/cpupower, которая
содержит все применяемые при запуске системы настройки. К примеру,
если вам нужно изменить политику масштабирования на постоянной основе,
то нужно указать значение параметра governor внутри
/etc/default/cpupower:
/etc/default/cpupower#governor='conservative'
Примечание
По умолчанию все строки в файле закоментированы. Чтобы
раскоментировать нужные параметры уберите знак # в начале
строки.
Отключение сторожевых таймеров#
Сторожевые таймеры (watchdog timer) - это аппаратные или программные средства, которые отслеживают зависания системы во время её работы. Все такие таймеры работают по принципу "пуллинга", при котором система должна постоянно выполнять прерывания таймера. Если прерывание не было сделано вовремя, то подразумевается, что система зависла и таймер по истечению времени ожидания должен сигнализировать другое устройство или программу (если речь о программном сторожевом таймере) о зависании, так чтобы были предприняты действия по автоматическому восстановлению работы системы, что может включать в себя её перезапуск или другие процедуры в зависимости от конкретной системы.
На первый взгляд это звучит очень здорово, однако стоит понимать, что сторожевые таймеры задумывались в основном для систем, которые должны работать полностью автономно без прямого участия со стороны пользователя. К ним относятся например сервера, SoC платы для встраивания в различные малые или крупные аппаратные комплексы (вплоть до таких систем как космические зонды) и т. д. На простых домашних ПК или ноутбуках у пользователя всегда есть возможность вручную выполнить перезапуск системы, не говоря о том, что как правило зависания достаточно мощных систем происходит редко и в основном из-за ошибок внутри самого ядра, а на маломощных в основном из-за ситуаций OOM (нехватки памяти).
Так как на домашних системах сторожевые таймеры большую часть времени выполняют только холостую работу, их отключение позволяет снизить общее энергопотребление [31] и увеличить производительность системы [32]. Сделать это можно как и всегда через соответствующий параметр sysctl:
/etc/sysctl.d/30-no-watchdog-timers.conf#kernel.watchdog = 0
К сожалению, на современных процессорах от AMD и Intel использование
данного параметра ядра недостаточно для полного отключения аппаратных
сторожевых таймеров [33], которые являются частью чипсета процессора.
Поэтому дополнительно требуется также запретить загрузку модулей ядра,
которые занимаются управлением этих таймеров. Для процессоров от Intel
это iTCO_wdt, а для AMD sp5100-tco. Чтобы запретить их
загрузку нужно создать файл в директории /etc/modprobe.d и внести
модули в чёрный список:
/etc/modprobe.d/30-blacklist-watchdog-timers.conf#blacklist sp5100-tco
blacklist iTCO_wdt
На системах под управлением дистрибутива Arch Linux или другого,
основанного на нем требуется, также выполнить обновление образов
initramfs, чтобы данная конфигурация для modprobe стала их частью
и была применена на этапе ранней загрузки системы:
sudo mkinitcpio -P
После перезагрузки системы можно удостовериться, что сторожевые
таймеры были успешно отключены через команду wdctl, она должна
вывести ошибку об отсутствии соответствующих устройств.
Отключение защиты от уязвимостей (по желанию)#
Осторожно
Данный раздел носит сугубо информационный характер и ни к чему не призывает. Безопасность системы является таким же важным её аспектом как и производительность, однако для тех, кто все же хочет "выжать максимум" несмотря на связанные с этим риски, и представлен материал ниже.
К сожалению современные процессоры (если говорить об архитектуре x86) обзавелись достаточно большим багажом аппаратных уязвимостей, которые приходится различными способами исправлять разработчикам ядра. И как правило все такие исправления влекут за собой большие потери производительности. Иногда такие исправления приводят к потерям порядка ~27-28% производительности [34] [35], а иногда и все 50% [36], как в случае с нашумевшей уязвимостью Spectre, что часто приводит к недоумению относительно целесообразности таких исправлений не только со стороны простых пользователей, но и со стороны других разработчиков ядра [37].
Здесь стоит отметить, что те же уязвимости Spectre и Meltdown сами по
себе не являются "прямым ключом" к вашей системе, так как даже при их
использовании скорость утечки в продемонстрированных ранее примерах
эксплуатации составляет всего 1 Кб/с. Кроме того, большинство
современных браузеров имеет свою встроенную систему защиты для запуска
всех критически важных процессов по обмену данными в изолированном
окружении, которое предотвращает эксплуатацию подобных уязвимостей,
хотя некоторые браузеры, например такие как Firefox, в последних
версиях отказываются от включения по умолчанию частей такой
дополнительной защиты в пользу лучшей производительности [38], в
частности на практике использование уязвимостей класса Spectre v2
имеет слабый практический характер, а также такая защита может быть не
нужна из-за включенной по умолчанию в ядре общей защиты против
уязвимостей класса Spectre. Если вы хотите форсировать включение этой
дополнительной защиты в Firefox вдобавок к уже существующим мерам
защиты в ядре, то сделать это можно через переменную окружения
MOZ_SANDBOX_NO_SPEC_ALLOW=1.
Если же вы все же решили выполнить полное отключение всей защиты в
ядре в пользу большей производительности, то сделать это можно только
при указании параметра загрузки ядра mitigations=off, который
следует прописать в конфигурации вашего загрузчика:
Предупреждение
Отключение защиты с целью повышения производительности имеет смысл только на старых поколениях процессоров Intel и AMD. На самых последних линейках это может иметь даже негативные последствия [39].
Чтобы изменить параметры по умолчанию к загрузке любого ядра при
использовании загрузчика GRUB 2 нужно открыть файл
/etc/default/grub, найти строку
GRUB_CMDLINE_LINUX_DEFAULT и внутрь двойных кавычек дописать
к уже имеющимся параметрам mitigations=off через пробел.
Пример такой строки конфигурации:
/etc/default/grub#...
GRUB_CMDLINE_LINUX_DEFAULT="quiet loglevel=3 mitigations=off"
...
После чего необходимо обновить конфигурацию загрузчика:
sudo grub-mkconfig -o /boot/grub/grub.cfg
Если вы используете загрузчик rEFInd вместе со всеми его
возможностями по автоматическому определению всех установленных
версией ядра у вас в системе, то чтобы добавить параметр
mitigations=off нужно отредактировать файл
/boot/refind_linux.conf и в первую строку содержащую
дописать данный параметр внутрь вторых двойных кавычек. Пример
такого файла конфигурации (не копировать полностью!):
/boot/refind_linux.conf#"Boot to default params" "root=PARTUUID=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX rw mitigations=off"
"Boot to single-user mode" "root=PARTUUID=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX rw single"
К сожалению при использовании загрузчика systemd-boot нельзя
указать общие для всех установленных ядер в системе параметры
загрузки, поэтому приходится указывать их в отдельности для
каждой версии ядра. Например, чтобы добавить параметр
mitigations=off для обычного ядра используемого в Arch
Linux, вам нужно найти файл внутри директории
/boot/efi/entries, который содержит строку linux
/vmlinuz-linux и ниже внутри этого файла дописать через пробел
параметр в строке с options. Пример конфигурации:
/boot/efi/loader/entries/arch.conf#title Arch Linux
linux /vmlinuz-linux
initrd /initramfs-linux.img
options root=UUID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx rw mitigations=off
Предупреждение
Путь до файла конфигурации может отличаться в
зависимости от того в какую директорию вы смонтировали
загрузочный раздел, некоторые пользователи вместо /boot/efi
используют точку монтирования /efi. Узнать используемую
точку монтирования можно через команду bootctl
--print-esp-path.